SadTalker:单张静态人脸图像和音频输入,生成逼真且风格化的3D动态谈话视频
SadTalker简介
SadTalker是由西安交通大学、腾讯AI实验室和蚂蚁集团的联合研究团队开发的一项先进技术。这项技术能够利用单张静态人脸图像和音频输入,生成逼真且风格化的3D动态谈话视频。通过创新的3D运动系数学习和3D感知人脸渲染,SadTalker在保持高视频质量和自然运动同步方面展现出卓越的性能,为数字人创建、视频会议等领域带来了重要的应用潜力。
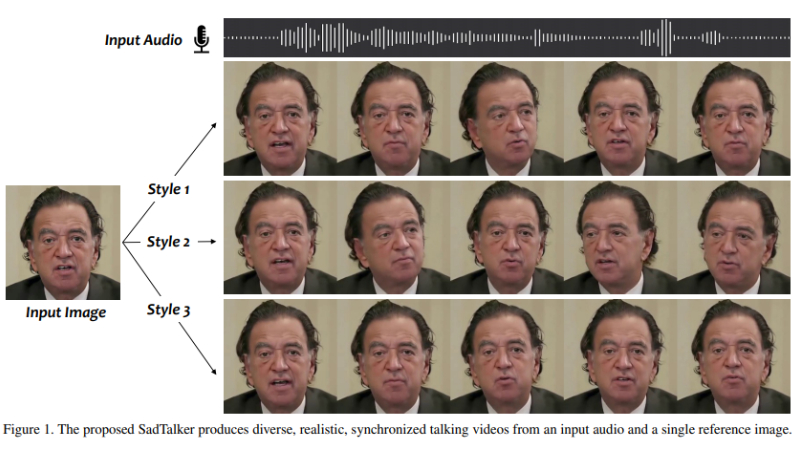
SadTalker主要功能
- 音频驱动的动画生成:SadTalker可以将输入的音频转换成与音频同步的动态人脸视频。
- 3D运动系数生成:系统能够从音频中提取头部姿势和表情的3D运动系数。
- 多样化风格支持:能够根据不同的风格生成多样化的头部运动和表情。
- 高真实感渲染:生成的视频具有高真实感,包括自然的表情和头部运动。
- 身份保持:在动画过程中保持原始图像中人物的身份特征。
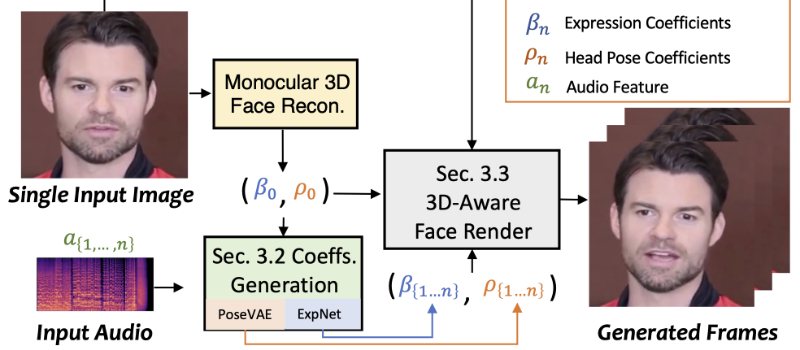
SadTalker技术原理
- 3D Morphable Models (3DMM):使用3DMM作为中间表示,将2D图像转换为3D面部模型。
- ExpNet:一个网络结构,用于从音频中学习准确的面部表情系数,通过提取音频特征并结合预训练的Wav2Lip模型和感知损失来实现。
- PoseVAE:条件变分自编码器,用于合成不同风格的头部运动,通过学习给定姿势的残差来实现。
- 3D-aware Face Render:一个新颖的3D感知人脸渲染器,它学习将3DMM系数映射到无监督的3D关键点空间,然后通过这些关键点生成最终视频。
- 运动系数的隐式调制:通过3D运动系数隐式调制人脸渲染过程,以生成逼真的动态视频。
- 端到端学习:SadTalker的各个子网络(如表情生成、头部姿势生成和人脸渲染器)可以独立训练,并且可以以端到端的方式进行推断。
- 多任务学习:系统同时学习从音频中提取表情和头部姿势,以减少不确定性并提高动画质量。
SadTalker应用场景
- 虚拟助手:为智能设备和应用程序提供更加自然和逼真的虚拟交互体验。
- 视频会议:增强远程通信的真实感,通过生成参与者的动态头像,提升会议体验。
- 社交媒体:用户可以创建个性化的动态表情或头像,用于社交媒体分享或互动。
- 电影和游戏制作:在电影或视频游戏中生成逼真的角色动画,减少传统动作捕捉的需求。
- 语言学习应用:为语言学习者提供嘴型同步的虚拟教师,增强发音学习体验。
- 个性化广告:根据用户的面部图像生成个性化的广告视频,提高广告的吸引力和相关性。
SadTalker项目入口
- 官方项目主页:https://sadtalker.github.io/
- GitHub代码库:https://github.com/OpenTalker/SadTalker
- arXiv研究论文:https://arxiv.org/pdf/2211.12194
- Hugging Face在线体验:https://huggingface.co/spaces/vinthony/SadTalker
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章
暂无评论...










一站式AI信息服务平台:AI工具大全、AI每日快讯、AI项目库、AI融资快报、AI研究报告、AI教程、AI副业、AI考证等。助您全面系统了解AI、使用AI


 粤公网安备44011102483711号
粤公网安备44011102483711号