Seed-ASR:可识别不同语言、方言、口音的AI语音识别模型
Seed-ASR简介
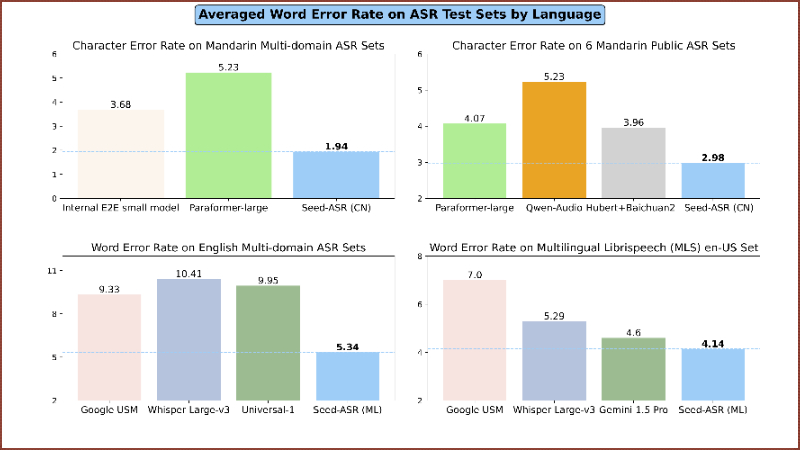
Seed-ASR是由字节跳动的Seed团队开发的一款基于大型语言模型(LLM)的语音识别模型。它通过结合超过2亿参数的音频编码器和具有数十亿参数的专家混合(MoE)LLM,实现了对多种语言、方言和口音的高准确度语音转文字能力。Seed-ASR在大规模训练和上下文感知能力方面表现出色,能够在多种应用场景中提供定制化的语音识别服务,显著提高了关键词的召回率,并在多语言和多方言的公共测试集上实现了显著的性能提升。
Seed-ASR主要功能
- 高精度识别:能够在多种领域、语言、口音和方言中实现准确的语音转写。
- 多语言支持:支持包括普通话和多种中国方言在内的超过40种语言的语音识别。
- 上下文感知:利用历史对话、视频编辑历史、会议参与详情等上下文信息来提高关键词的识别率。
- 大规模训练:基于超过2000万小时的语音数据和近90万小时的配对ASR数据进行训练。
- 定制化能力:根据不同应用场景的特定需求调整模型,以适应不同的语音类型和上下文。
Seed-ASR技术原理
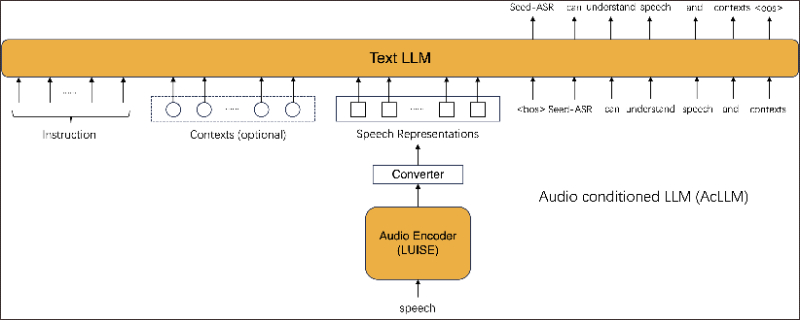
- 音频条件大型语言模型(AcLLM):Seed-ASR基于AcLLM框架,将连续的语音表示与上下文信息一起输入到LLM中。
- 大规模自监督学习(SSL):使用LUISE,一个具有近20亿参数的音频编码器,通过自监督学习捕捉语音信号中的全局和局部结构。
- 监督式微调(SFT):在大量语音-文本对数据上进行训练,建立语音与文本之间的映射关系。
- 上下文微调(Context SFT):使用上下文-语音-文本三元组数据来训练模型,提高模型从上下文中捕获与语音内容相关的线索的能力。
- 强化学习(RL):通过基于ASR指标的奖励函数,进一步优化模型的文本生成行为,特别是对语义重要部分的转录。
- 联合束搜索(Joint Beam Search):一种解码策略,用于解决直接使用原生束搜索时的严重幻觉问题,通过平衡语音信息和上下文信息的重要性来提高识别的准确性。
- 最小词错误率(MWER):作为RL阶段的另一个训练目标,与交叉熵目标函数相结合,强调关键词错误的重要性。
Seed-ASR应用场景
- 智能助手:在智能手机和个人助理设备中提供语音到文本的转换,帮助用户通过语音命令执行任务。
- 会议记录:在商务会议或网络研讨会中自动记录会议内容,生成文字记录,便于后续回顾和分析。
- 客户服务:在呼叫中心自动转录客户对话,用于服务质量监控或作为培训材料。
- 语言学习:辅助语言学习者练习发音和听力,提供实时反馈和改进建议。
- 媒体和娱乐:在电影、电视节目的后期制作中自动生成字幕,提高工作效率。
- 医疗记录:在医院或诊所中记录医生和患者的对话,以便快速整理成电子病历。
Seed-ASR项目入口
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章
暂无评论...










一站式AI信息服务平台:AI工具大全、AI每日快讯、AI项目库、AI融资快报、AI研究报告、AI教程、AI副业、AI考证等。助您全面系统了解AI、使用AI


 粤公网安备44011102483711号
粤公网安备44011102483711号