Show-o简介
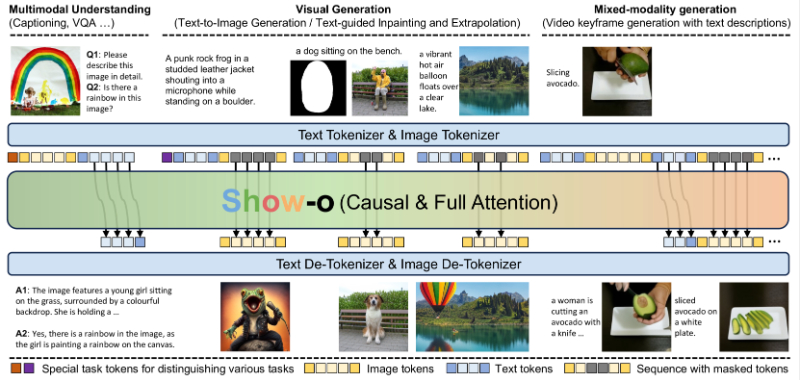
Show-o是由新加坡国立大学的Show Lab和字节跳动公司联合开发的一个创新的统一变换器模型。它通过结合自回归和离散扩散建模,有效地整合了多模态理解和生成能力。Show-o能够灵活处理包括视觉问题回答、文本到图像生成、文本引导的修复和扩展,以及混合模态生成在内的广泛视觉-语言任务。这一模型在各种基准测试中展现出与现有专门针对理解或生成的模型相当或更优越的性能,突显了其作为下一代基础模型的潜力。

Show-o主要功能
- 多模态理解:能够处理包括视觉问题解答(VQA)在内的多模态理解任务,理解和解释视觉内容。
- 文本到图像生成:根据文本描述生成相应的图像,支持创意和多样化的视觉输出。
- 文本引导的修复与扩展:对图像进行文本引导的修复(inpainting)和扩展(extrapolation),例如填补图像缺失部分或在图像中添加新元素。
- 混合模态生成:结合文本描述生成视频关键帧,为长视频生成提供可能性。
Show-o技术原理
- 自回归与扩散建模的统一:Show-o结合了自回归模型和扩散模型的优势,自回归用于文本建模,而扩散模型用于图像生成。
- 多模态输入处理:使用文本分词器和图像分词器将输入数据编码为离散的标记,实现对不同模态数据的统一处理。
- 全注意力机制(Omni-Attention):根据输入序列的不同,自适应地混合和切换因果注意力(用于文本)和全注意力(用于图像)。
- 统一提示策略(Unified Prompting):通过设计统一的提示格式,将各种类型的输入数据编码为序列化数据,以支持多模态理解和生成任务。
- 训练方法的创新:采用三阶段训练流程,包括图像标记嵌入学习、图像-文本对齐训练,以及高质量数据微调,确保模型在多模态任务上的有效性。
- 编码器和分词器的优化:利用MAGVIT-v2量化器将图像编码为离散的标记,并考虑使用CLIP-ViT等连续表示方法来提升多模态理解的能力。
Show-o应用场景
- 社交媒体内容创作:用户可以提供文本描述,Show-o生成相应的图像或视频,丰富社交媒体帖子。
- 虚拟助手:在虚拟环境中,根据用户的查询或指令,生成解释性图像或动画,提供视觉辅助。
- 教育和培训:生成教学材料中的图表、图解和示例图像,增强学习体验。
- 广告和营销:根据产品描述或营销概念快速生成吸引人的视觉内容,用于广告宣传。
- 游戏开发:为视频游戏设计生成独特的游戏环境、角色和物品图像。
- 电影和视频制作:辅助前期制作,根据剧本生成概念艺术和场景设计图。
Show-o项目入口
- 官方项目主页:https://showlab.github.io/Show-o/
- GitHub源码库:https://github.com/showlab/Show-o
- arXiv研究论文:https://arxiv.org/abs/2408.12528
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章
暂无评论...










一站式AI信息服务平台:AI工具大全、AI每日快讯、AI项目库、AI融资快报、AI研究报告、AI教程、AI副业、AI考证等。助您全面系统了解AI、使用AI


 粤公网安备44011102483711号
粤公网安备44011102483711号