Qwen2-VL:阿里巴巴达摩院最新推出的视觉语言模型
Qwen2-VL简介
Qwen2-VL是阿里巴巴达摩院最新推出的视觉语言模型,具备卓越的图像和视频理解能力。它能够处理不同分辨率和长宽比的图片,理解长达20分钟的视频,并支持多语言文本识别。此外,Qwen2-VL 还能作为视觉智能体,集成到手机和机器人中,执行基于视觉环境的操作。模型在多个基准测试中表现优异,尤其在文档理解和多语言文字识别方面。它以 Apache 2.0 协议开源,支持开发者在多种应用场景中实现创新。

Qwen2-VL主要功能
- 多分辨率图像理解:Qwen2-VL 能够读懂不同分辨率和长宽比的图片,处理各种视觉内容。
- 长视频理解:模型能够理解长达20分钟的视频,适用于视频问答和内容创作。
- 视觉智能体操作:集成到手机和机器人等设备,根据视觉环境和文字指令自动执行任务。
- 多语言支持:除了英语和中文,还支持包括欧洲语言、日语、韩语等在内的多语言文本理解。
- 细节识别与理解:增强了对图像中手写文字和多种语言的识别能力,提升了全球易用性。
- 视觉推理:通过分析图像解决问题,解读复杂数学问题,从真实世界图像和图表中提取信息。
- 视频内容分析:总结视频要点,即时回答相关问题,并维持连贯对话。
- 视觉代理能力:具备函数调用和视觉交互能力,可以执行自动化工具调用和环境交互。
Qwen2-VL技术原理
- Vision Transformer (ViT): 作为模型的视觉处理核心,ViT 能够处理图像和视频数据,将视觉内容转换为模型可以理解的格式。
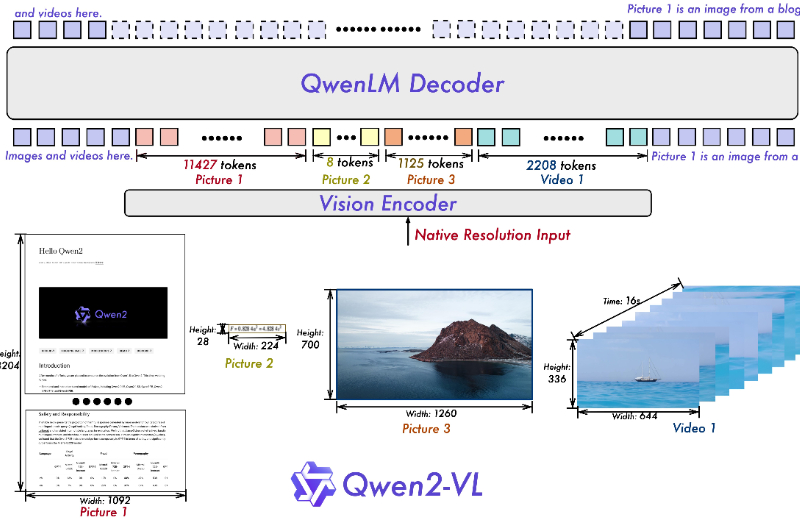
- 动态分辨率支持: Qwen2-VL 能够处理任意分辨率的图像,通过动态调整 tokens 的数量来适应不同大小的图像,从而保持视觉信息的完整性。
- 多模态旋转位置嵌入 (M-ROPE): 这是一种先进的位置编码技术,允许模型同时捕捉和整合文本序列、二维图像和三维视频的位置信息,增强了模型对多模态数据的理解能力。
- 大规模参数训练: Qwen2-VL 提供了不同规模的模型版本,通过大量参数训练,提升了模型在各种视觉任务上的性能。
- 开源框架集成: 模型代码与 Hugging Face Transformers、vLLM 等开源框架集成,使得开发者可以轻松地在这些框架上部署和使用 Qwen2-VL。
- 量化模型支持: 提供量化版本的模型,优化了模型的性能和资源消耗,使其更适合在资源受限的环境中运行。
- API 和微调工具: 通过官方 API 和微调工具,用户可以根据自己的需求定制模型,提高其在特定任务上的表现。
- 多模态数据处理能力: Qwen2-VL 能够处理和理解包括图像、文本和视频在内的多种类型的数据,实现多模态交互和理解,这是其技术原理中的一个重要方面。
Qwen2-VL模型性能
他们的模型在视觉能力评估中表现出色,涵盖了大学题目解答、数学解题、文档表格理解、多语言文字图像识别、通用场景问答和视频理解等多个方面。72B规模的模型在多数指标上超越了业界领先的闭源模型,尤其在文档理解方面表现突出。7B规模的模型在经济性和性能上取得了平衡,特别是在文档和图像理解任务上达到了行业领先水平。此外,他们还推出了2B规模的模型,以满足移动端应用的需求,该模型在视频文档理解和通用场景问答方面相较于同规模模型具有显著优势。

Qwen2-VL应用场景
- 智能客服与助手:Qwen2-VL 可用于构建能够理解用户上传图片和视频的智能客服系统,提供更直观、个性化的服务体验。
- 内容审核:在社交媒体和在线平台上,模型可以辅助识别和过滤不当的视觉内容,维护网络环境的健康。
- 教育与学习辅助:Qwen2-VL 能够辅助学生理解复杂概念,通过图像和视频提供更加直观的学习材料。
- 医疗影像分析:在医疗领域,模型可以帮助分析医学影像,辅助医生进行诊断,提高医疗服务的效率和准确性。
- 自动驾驶:集成到自动驾驶系统中,Qwen2-VL 能够处理和理解车辆摄像头捕获的实时视觉信息,提高驾驶安全性。
- 智能家居控制:在智能家居环境中,模型可以识别家中的视觉信息,如手势和面部表情,实现更自然的交互和控制。
Qwen2-VL项目入口
- 官方项目主页:https://qwenlm.github.io/zh/blog/qwen2-vl/
- GitHub代码库:https://github.com/QwenLM/Qwen2-VL
- HuggingFace模型:https://huggingface.co/collections/Qwen/qwen2-vl
- Modelscope:https://modelscope.cn/organization/qwen?tab=model
- 在线体验:https://huggingface.co/spaces/Qwen/Qwen2-VL
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章
暂无评论...










一站式AI信息服务平台:AI工具大全、AI每日快讯、AI项目库、AI融资快报、AI研究报告、AI教程、AI副业、AI考证等。助您全面系统了解AI、使用AI


 粤公网安备44011102483711号
粤公网安备44011102483711号