GLM-4V-Plus:智谱AI推出的图像和视频理解模型
GLM-4V-Plus简介
GLM-4V-Plus是智谱AI推出的一款先进的图像和视频理解模型,它具备出众的图像识别能力和基于时间序列分析的视频理解技术。该模型通过深度学习算法强化了对视觉内容的解析和理解,能够准确地捕捉和分析图像及视频中的关键信息。作为国内首个通用视频理解能力的API,GLM-4V-Plus不仅支持图像内容的识别和描述,还能够将网页内容转化为HTML代码,为用户提供了一种全新的视觉数据处理方式。其应用场景广泛,从视频分析到内容创作,都能提供高效、精准的视觉智能服务。

GLM-4V-Plus主要功能
- 能够同时处理图像和视频数据,提供对视觉内容的深入理解。
- 对静态图片进行精准分析,识别图片中的元素和场景。
- 理解视频内容,包括其中的对象识别和动作捕捉,以及事件的序列分析。
- 具备时间感知,能够理解视频内容中随时间发展的变化。
- 提供API接口,允许开发者轻松将视频理解功能集成到自己的应用中。
- 支持与用户的实时交互,能够快速响应视频内容相关的查询和指令。
GLM-4V-Plus模型性能
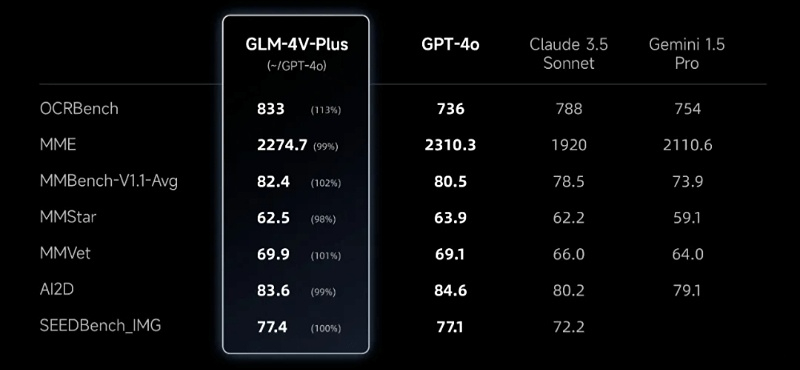
GLM-4V-Plus的各项指标接近GPT-4o,在图像和视频理解方面达到了国际先进水平
GLM-4V-Plus应用场景
- 在内容审核中,自动筛选和标记不适宜的视频内容。
- 用于安全监控,自动检测并报告监控视频中的异常活动。
- 辅助教育,分析教育视频,为学生提供个性化反馈。
- 为自动驾驶技术提供视觉识别支持,增强环境感知能力。
- 分析运动表现,为运动员提供技术改进的建议。
- 在娱乐行业,用于自动化处理和标记影视作品中的关键片段。
GLM-4V-Plus项目入口
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章
暂无评论...










一站式AI信息服务平台:AI工具大全、AI每日快讯、AI项目库、AI融资快报、AI研究报告、AI教程、AI副业、AI考证等。助您全面系统了解AI、使用AI


 粤公网安备44011102483711号
粤公网安备44011102483711号