VideoGameBunny:专为理解视频游戏图像而设计的多模态模型
VideoGameBunny简介
VideoGameBunny是一个专为理解视频游戏图像而设计的多模态模型,基于Bunny模型并采用LLaVA风格架构。它通过分析来自413款游戏的185,259张图像以及相应的389,565个图像-指令对,展现出在游戏内容理解任务上超越现有大型模型的潜力。该模型能够准确识别游戏中的场景、角色、物品等元素,并响应相关问题,为提升游戏体验、辅助游戏开发和自动化测试提供了新的可能性。研究者还发布了与之配套的数据集和训练资源,以推动视频游戏领域的人工智能研究。

VideoGameBunny主要功能
- 图像理解: VideoGameBunny能够理解视频游戏中的图像内容,包括场景、角色、物体等。
- 问题回答: 针对视频游戏图像提出的问题,模型能够提供准确的答案。
- 图像描述: 能够生成图像的详细描述,包括场景概述、角色状态、环境特征等。
- 异常检测: 识别游戏中可能存在的异常或错误,如图像错误或逻辑错误。
- 交互辅助: 辅助玩家通过理解游戏环境和提供指导来完成任务。
- 自动化测试: 辅助游戏开发过程中的自动化测试,通过识别和报告可能的错误。
VideoGameBunny技术原理
- 多模态学习: 结合图像和文本数据,使模型能够处理和理解来自不同源的信息。
- 深度学习架构: 使用基于深度学习的网络,如多层感知器(MLP)和变换器(Transformer),来处理复杂的数据模式。
- 图像特征提取: 利用预训练的视觉模型(如SigLIP)来提取图像特征,并将其转换为模型可以理解的格式。
- 语言模型集成: 将图像特征与先进的语言模型(如Llama-3)结合,以生成文本输出。
- 微调技术: 在特定于视频游戏的数据集上微调模型,以提高其在游戏相关内容上的性能。
- 数据集构建: 创建和使用大规模的、多样化的视频游戏图像数据集,包括图像标题、问答对和JSON格式的图像描述。
- 指令遵循: 通过指令调用来提高模型对用户指令的响应能力,使其能够执行特定的任务或回答问题。
- 模型优化: 采用参数效率的微调方法(如LoRA),在保持较小模型大小的同时提高性能。
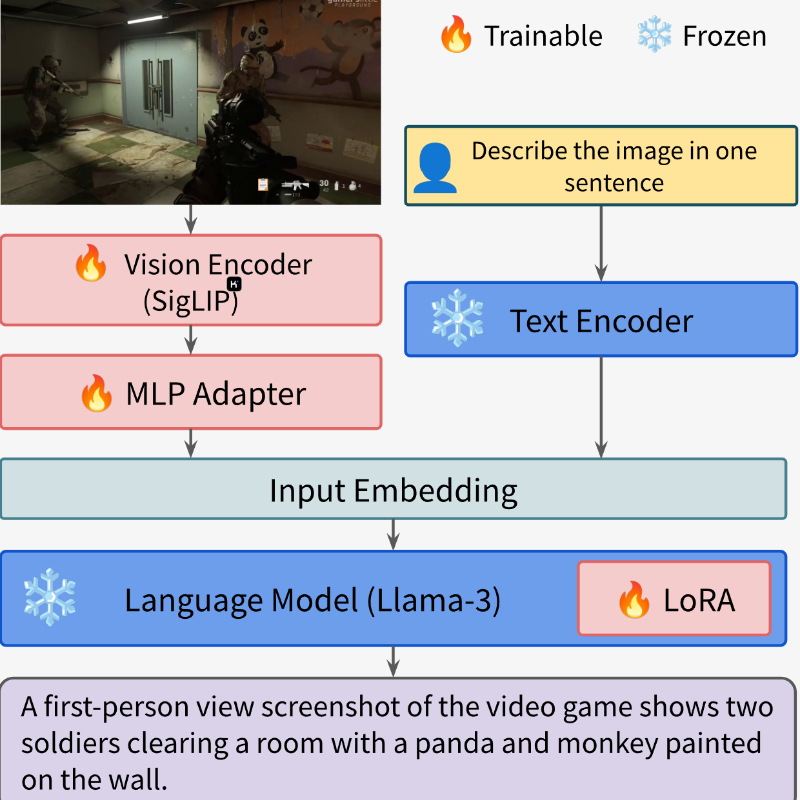
VideoGameBunny应用场景
- 游戏内辅助: 在游戏中,VideoGameBunny可以作为虚拟助手,帮助玩家理解复杂的游戏机制或提供任务指导,提升玩家的游戏体验。
- 游戏测试与质量保证: 利用模型识别游戏中的图像错误和逻辑漏洞,自动化测试过程,提高游戏发布前的质量控制效率。
- 游戏内容创作: 辅助游戏开发者在设计游戏环境、角色和物品时,通过提供图像描述和反馈,加速创意实现过程。
- 游戏教学与解说: 作为教学工具,为新玩家提供实时的游戏指导,或者作为解说工具,为观众提供游戏过程中的深入分析。
- 游戏数据分析: 对玩家的游戏行为和游戏内事件进行图像分析,为游戏设计师提供玩家行为的洞见,帮助他们优化游戏设计。
- 游戏玩家支持: 提供多语言的游戏支持服务,帮助玩家解决游戏中遇到的问题,提升玩家满意度和游戏社区的互动。
VideoGameBunny项目入口
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章
暂无评论...










一站式AI信息服务平台:AI工具大全、AI每日快讯、AI项目库、AI融资快报、AI研究报告、AI教程、AI副业、AI考证等。助您全面系统了解AI、使用AI


 粤公网安备44011102483711号
粤公网安备44011102483711号