Mini-Omni简介
Mini-Omni 是由清华大学推出的一款多模态大型语言模型,它具备实时语音交互的能力,能够直接处理音频输入并即时输出语音,实现流畅的对话体验。该模型采用端到端的设计,通过一种新颖的文本指令语音生成方法和批量并行推理策略,显著提升了性能。Mini-Omni 不仅保留了传统语言模型强大的文本处理能力,还通过“Any Model Can Talk”训练方法,使得其他模型也能快速获得语音交互功能。此外,研究团队还推出了 VoiceAssistant-400K 数据集,专门用于优化语音助手模型的微调,推动了语言模型在实时语音交互领域的研究和应用。
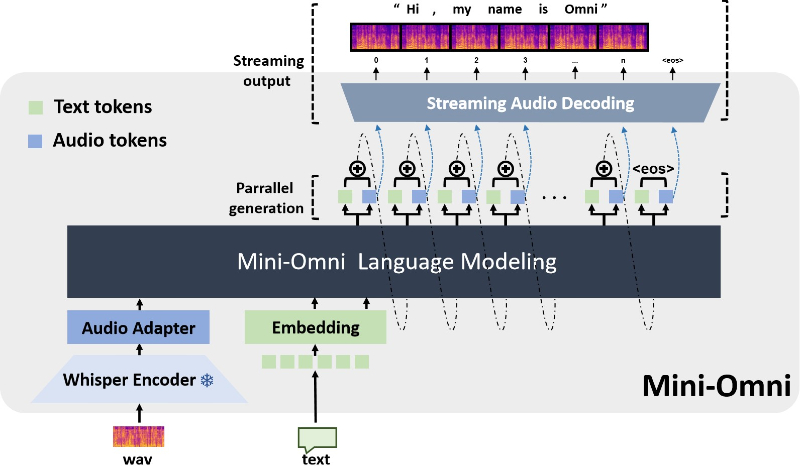
Mini-Omni主要功能
- 实时语音交互:Mini-Omni能够实现实时的语音输入和输出,使得与模型的对话像与人交谈一样自然流畅。
- 文本指令的语音生成:模型采用文本指令来引导语音的生成,提高了语音输出的准确性和相关性。
- 端到端对话能力:作为一个完全端到端的模型,Mini-Omni整合了语音识别、理解和生成的能力,无需依赖额外的系统或工具。
- 保留语言模型能力:在增加语音交互功能的同时,Mini-Omni能够保持原有语言模型在文本处理上的性能和能力。
- 开源和可扩展性:模型开源,提供了代码和数据,支持研究者和开发者进行进一步的研究和定制开发。
Mini-Omni技术原理
- 音频基础模型:Mini-Omni基于现有的语言模型架构,通过添加音频处理模块来实现对语音的理解和生成。
- 文本-音频并行解码:模型能够同时生成文本和音频输出,利用文本输出的信息密度高的特点,通过文本指令来引导音频的生成。
- 批量并行策略:在推理过程中,模型采用批量并行处理技术,提高了音频输出的效率和模型在语音任务上的表现。
- 音频编码器:选用高效的音频编码器(如SNAC),以保证音频输出的质量,同时减少模型推理的复杂度。
- “Any Model Can Talk”方法:这是一种训练方法,允许通过最小的改动和额外数据,让任何模型快速获得语音生成的能力。
- VoiceAssistant-400K 数据集:为了优化模型的语音输出,特别是对话场景下的语音助手风格,研究团队创建了专门的数据集进行微调。
Mini-Omni应用场景
- 智能个人助理:作为用户的虚拟助手,提供日程管理、信息查询、提醒和日常任务自动化等服务。
- 客户服务:在企业的客户服务中心,通过语音交互处理客户咨询、投诉和技术支持,提高服务效率。
- 语言学习辅助:为语言学习者提供实时语音对话练习,模拟真实对话环境,帮助提升口语和听力技能。
- 智能家居控制:集成到智能家居系统中,通过语音指令控制家中的智能设备,如灯光、温度和安全系统。
- 车载系统:在车辆中提供语音交互界面,使驾驶员能够通过语音控制导航、音乐播放和通讯功能,提高驾驶安全性。
- 健康咨询:在医疗健康领域,通过语音交互提供健康咨询、症状分析和预约安排,辅助医生和患者之间的沟通。
Mini-Omni项目入口
- GitHub代码库:https://github.com/gpt-omni/mini-omni
- Hugging Face:https://huggingface.co/gpt-omni/mini-omni
- arXiv研究论文:https://arxiv.org/pdf/2408.16725
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章
暂无评论...










一站式AI信息服务平台:AI工具大全、AI每日快讯、AI项目库、AI融资快报、AI研究报告、AI教程、AI副业、AI考证等。助您全面系统了解AI、使用AI


 粤公网安备44011102483711号
粤公网安备44011102483711号