Hallo3:能够创建高度动态和逼真的肖像动画视频
Hallo3简介
Hallo3是由复旦大学和百度公司联合开发的一种先进的肖像图像动画技术。它利用基于扩散变换器网络的预训练视频生成模型,能够创建高度动态和逼真的肖像动画视频。该技术通过创新的身份保持机制、语音音频条件处理以及视频外推策略,有效解决了非正面视角处理、动态对象渲染和沉浸式背景生成等挑战。Hallo3在多个基准和新提出的数据集上进行了验证,显示出在生成多样化朝向和动态场景中的逼真肖像方面相较于先前方法有显著提升。此外,开发团队还提供了进一步的可视化和源代码,以促进学术交流和技术应用。
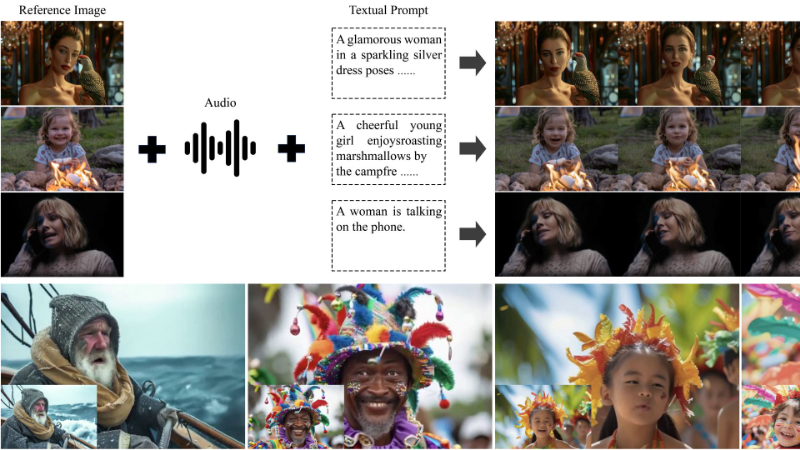
Hallo3主要功能
-
生成高度动态和逼真的肖像动画视频:Hallo3能够基于输入的肖像图像、音频序列和文本提示,生成具有丰富表情、嘴唇动作和头部姿势的动画视频。
-
处理非正面视角:有效解决现有方法在处理侧面、俯视或仰视等非正面视角肖像动画时的挑战,生成自然流畅的动画。
-
渲染动态前景和背景:不仅关注面部动画,还能生成与主体互动的前景对象(如手机、麦克风)和动态背景(如篝火、拥挤街道),增强视频的真实感和沉浸感。
-
长期身份保持:在整个视频序列中保持面部身份的一致性,即使在长时间的动画中也能确保面部特征的稳定性和连贯性。
Hallo3技术原理
-
预训练的变换器视频生成模型:
-
模型架构:基于CogVideoX模型,采用3D变分自编码器(3D VAE)进行视频数据压缩,将潜在变量与文本嵌入结合,通过专家变换器网络处理。
-
条件机制:引入语音音频条件(caudio)和身份外观条件(cid),通过交叉注意力(cross-attention)和自适应层归一化(adaLN)等机制进行条件嵌入。
-
-
身份保持机制:
-
身份参考网络:使用因果3D VAE结合变换器层的堆叠,提取参考图像的身份特征,并将其嵌入到去噪潜在代码中,确保面部身份在视频序列中的长期一致性。
-
特征融合:将参考网络生成的视觉特征与去噪网络的特征进行融合,增强模型生成连贯和身份一致的面部动画的能力。
-
-
语音音频条件处理:
-
音频嵌入:利用wav2vec框架提取音频特征,生成全面的语义表示,捕捉语音的层次结构。
-
条件融合策略:通过交叉注意力机制将音频嵌入与潜在编码进行交互,增强生成输出的连贯性和相关性,确保模型有效捕捉驱动角色生成的音频信号。
-
-
视频外推策略:
-
运动帧条件:引入生成视频的最后几帧作为运动帧,作为后续视频生成的条件信息,实现长时间视频的连贯生成。
-
零填充和拼接:对运动帧进行3D VAE处理,获取潜在代码,并与高斯噪声拼接,输入到去噪网络中,实现时间一致的长视频推理。
-
-
训练和推理过程:
-
训练阶段:
-
身份一致性阶段:固定3D VAE和面部图像编码器的参数,更新参考网络和去噪网络中的3D全注意力块和面部注意力块的参数。
-
音频驱动视频生成阶段:集成音频注意力模块,固定其他组件的参数,更新音频注意力模块的参数。
-
-
推理阶段:模型接收参考图像、驱动音频、文本提示和运动帧作为输入,生成具有身份一致性和嘴唇同步的视频,通过使用前一个视频的最后两帧作为运动帧,实现时间一致的视频生成。
-
Hallo3应用场景
-
电影和动画制作:生成逼真的角色动画,减少手工建模和动画制作的时间和成本。
-
游戏开发:创建动态的游戏角色和NPC,提升游戏的沉浸感和互动性。
-
社交媒体内容创作:为用户提供个性化的动画头像和动态图片,增强内容的趣味性和吸引力。
-
在线教育和培训:生成虚拟教师或培训师的动画,提供更加生动和互动的学习体验。
-
虚拟现实(VR)和增强现实(AR):在VR和AR应用中创建逼真的虚拟角色,提升用户的沉浸感。
-
广告和营销:制作个性化的广告动画,吸引观众的注意力,提高广告效果。
Hallo3项目入口
© 版权声明
文章版权归作者所有,未经允许请勿转载。

相关文章
暂无评论...










一站式AI信息服务平台:AI工具大全、AI每日快讯、AI项目库、AI融资快报、AI研究报告、AI教程、AI副业、AI考证等。助您全面系统了解AI、使用AI


 粤公网安备44011102483711号
粤公网安备44011102483711号