











豆包大模型简介
豆包大模型是由字节跳动公司开发的大型人工智能模型,它在多个领域展现出了强大的能力。最近,豆包大模型家族迎来了新成员,包括豆包・视频生成模型(含 豆包PixelDance、豆包Seaweed两款) 、豆包音乐模型和豆包・同声传译模型。这些新模型的加入,使得豆包大模型在视觉、语音等多模态能力上得到了显著提升。豆包・视频生成模型特别引人注目,它能够根据文本提示生成高质量的视频内容,具有精准的语义理解能力和强大的动态效果。这个模型能够处理复杂的指令,生成包含多个动作和主体交互的视频,同时保持画面的自然度和逻辑连贯性。它还支持多种风格和比例,能够生成接近专业人类视频工作者水平的视频内容。
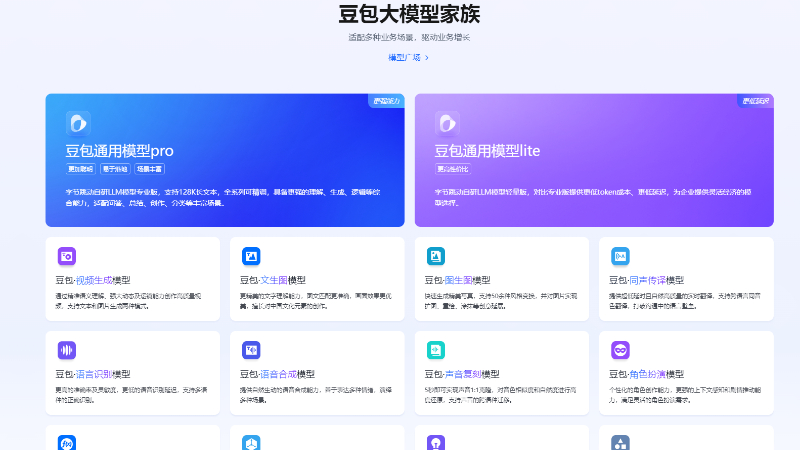
豆包大模型主要功能
- 视频生成:能够根据文本提示生成高质量的视频内容,支持多动作多主体交互,具备强大的动态效果和炫酷的运镜技巧。
- 音乐生成:可以基于文本或图片创作音乐,支持多种风格和情感色彩的音乐创作。
- 同声传译:提供准确、实时的同声传译服务,支持音色克隆,实现真正的同声传译。
- 图像生成:根据文本描述生成相应的图像,支持多种风格和艺术形式。
- 语音识别与合成:能够识别语音并将其转换为文本,以及将文本合成为语音
豆包大模型应用场景
- 电商营销:快速生成商品的动态展示视频,提升在线销售转化率。
- 动画教育:降低动画制作成本,生动呈现教育内容。
- 城市文旅宣传:制作引人入胜的城市旅游宣传片。
- 音乐MV制作:创作与音乐情感相匹配的MV。
- 微电影和短剧制作:快速制作具有故事性的视频内容。
- 社交媒体内容创作:为社交媒体平台定制短视频,增加用户参与度和分享率。
- 企业宣传:制作企业宣传片,有效传达企业文化和价值主张。
相关导航





暂无评论...








一站式AI信息服务平台:AI工具大全、AI每日快讯、AI项目库、AI融资快报、AI研究报告、AI教程、AI副业、AI考证等。助您全面系统了解AI、使用AI


 粤公网安备44011102483711号
粤公网安备44011102483711号